Big Match: matching open source code in binaries for fun and profit
Technical
Do you do reverse engineering for a living? Have you ever wasted several weeks reversing an open source library embedded in a target? Do you crave for better tools than copy-pasting random strings into Google?
No?
Well, read anyway.
-- babush
Today we are proud of showing the world the first prototype of Big Match, our tool to find open-source libraries in binaries only using their strings. How does it work? Read this post to find out, or head to our demo website to try it out.
Spoiler: we are analyzing all the repositories on GitHub and building a search engine on top of that data.
Introduction
There's a thing that every good reverser does when starting to work on a target: look for interesting strings and throw them into Google hoping to find some open-source or leaked source. This can save you anywhere from few hours of work to several days. It's kind of a poor man's function (or library) matching.
In 2018, I decided to try out LINE's Bug Bounty program and so I started reversing a library bundled with the Android version of the App.
For those unfamiliar with LINE, it's the most used instant messaging App in Japan.
Anyway, there were many useful error strings sprinkled all around my target, so I did exactly that manual googling I've just mentioned.
Luckily, I was able to match some strings against Cisco's libsrtp.
But little did I know, my target included a modified version of PJSIP, a huge library that does indeed include libsrtp.
Unfortunately, I discovered this fact much later, so I wasted an entire week reversing an open-source library.
So, I thought: "can we do better than manual googling? Why hasn't anyone built a huge database of all the strings in every public repository?". And, just like that, the main idea for Big Match was born.
Outline of our approach
The way we, at rev.ng, decided to approach this problem is actually simple conceptually, but gets tricky due to the scale of the data we are dealing with.
In short, this is the outline of what we did:
- Get the source code of the top C/C++ repositories on GitHub, where "top" means "most starred". Ideally we would like to analyze all of them, and we will eventually, but we wanted to give priority to famous projects.
- Deduplicate the repositories: we don't want to have 70k+ slightly different versions of the Linux kernel in our database.
- Extract the strings: use
ripgrepas a quick way to extract strings from source code. - De-escape the strings. E.g.: turn
'\n'into an actual newline character. - Hash the strings.
- Store them in some kind of database.
- Query the database using the hashes of the strings from a target binary.
- Cluster the query results.
Where to start
The first thing we did was figure out a way to get the list of all the repos on GitHub, sorted by stars. It turns out, however, that this is more easily said than done. GitHub has an official API but it is rate-limited and we wanted to avoid writing a multi-machine crawling system just for that. So we looked around and, among many projects making available GitHub data, we found the amazing GHTorrent.
GHTorrent, short for GitHub Torrent, is a project created by Prof. Georgios Gousios of TU Delft.
What it does is periodically poll GitHub's public events API and use the information on commits and new repositories to record the history of GitHub.
So, for example, if user thebabush pushes some changes to his repository awesome-repo, GHTorrent analyzes those changes and, if the repo is not present in its database, it creates a new entry.
It also saves its metadata, e.g. star count, and some of its commits.
By exploiting the GitHub REST API, GHTorrent is able to create a somewhat complete relational view of all of GitHub (except for the actual source code):

GHTorrent's data is made available as either a MySQL dump of the relational database in the picture or as a series of daily MongoDB dumps. GHTorrent uses Mongo as a caching layer for GitHub's API so that it can avoid making the same API call twice.
Once you import the GHTorrent MySQL dumps on your machine, you can quickly get useful information about GitHub using good ol' SQL (e.g.: information about the most popular C/C++ repos is a simple SELECT ... WHERE ... ORDER BY ...).
It also contains information about forks and commits, so you have some good data to exploit for the repo deduplication we want to do.
However, GHTorrent is best-effort by design, so you'll never have a complete and consistent snapshot of GitHub. For example, some repos might be missing or have outdated metadata. Another example is that commits information is partial: GHTorrent cannot possibly associate every commit to every repository containing it. Think about the Linux kernel: one commit would need to be added to 70k+ forks and that kind of things doesn't scale very well.
Finally, there's another risk regarding the use of a project like GHTorrent: maintenance. Keeping a crawler working costs money and time, and it seems like in the last couple of years they haven't been releasing MySQL dumps that often anymore. On the other hand, they still release their incremental Mongo updates daily. Since they create the MySQL DB using REST API calls that are cached through MongoDB, those incremental updates should be everything you need to recreate their MySQL database.
A fun fact is that Microsoft used to sponsor GHTorrent, but I guess they don't need to do it now 🙃. And yes, that's not a good thing for us.
In the end, since we don't actually need all the tables provided by the GHTorrent MySQL dump, we decided to write a script that directly consumes their Mongo dumps one by one and outputs the information we need into a bunch of text files. In fact, most of our pipeline is implemented using bash scripts (you can read more in our future blogpost about what we like to call bashML).
Repository deduplication
We mentioned in the outline that we need to deduplicate the repositories. We need to do that for several reasons:
- As stated earlier, we don't want to download every single fork of every single famous project out there.
- Duplicated data means that our database of repos grows very fast in size. The first ~100K repos we downloaded from GitHub amount to ~1.4TB of
gzip'd source code (withoutgithistory), so you can see why this is an important point. - Duplicated data is bad for search results accuracy.
GHTorrent has information about forks but, as for GitHub itself, that only counts forks created with the "Fork" button on the web UI. The other option is to look for common commits between repositories. If we had infinite computing resources, we would do this:
- Clone every repository we care about.
- Put every commit hash in a graph database of some kind.
- Connect commit hashes using their parent/child relationship.
- Find the root commits.
- For every root commit, keep only the most-starred repo.
However, we live in the real world, so this is simply impossible for us to do. We would like to have a strategy to deduplicate repos before cloning them, as cloning would require a lot of time and bandwidth. On top of that, when using git you can merge the history of totally-unrelated projects. So, if you deduplicate repos based on the root commit alone, you end up removing a lot of projects you actually want to keep.
Case in point: octocat/Spoon-Knife.
Octocat
octocat/Spoon-Knife is the most forked project on GitHub, and there's a reason for that: it's the repo that is used in GitHub's tutorial on forking.
This means that a lot of people learning to use GitHub have forked this repo at some point.
You might be wondering why Spoon-Knife causes troubles to our theoretical deduplication algorithm.
Well, take a look at this screenshot of LibreCAD's git history:
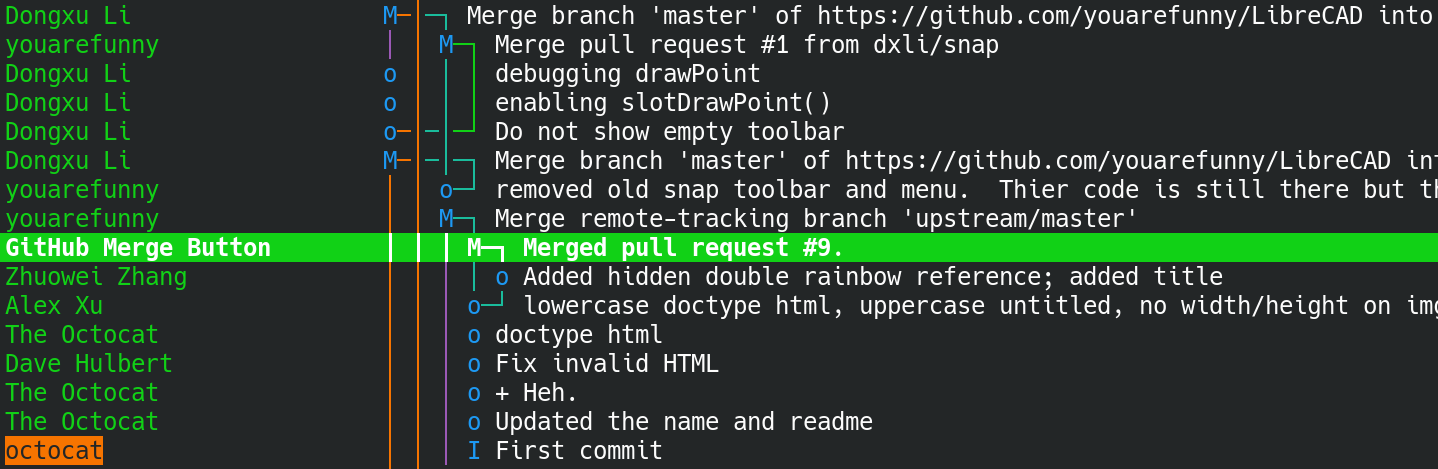
At some point in the past some user by the name of youarefunny was learning to use GitHub and so he forked Spoon-Knife.
At some other point, he forked LibreCAD and made some commits.
Then, for whatever reason, he thought "well, why not merge the history of these two nice repositories in a single one? So we can have a branch with the history of both projects!".
And finally, just to fuck with us contribute to a useful open-source project like LibreCAD, he decided to open a pull request using that exact branch.
And that pull request was accepted.
TL;DR: the history of Spoon-Knife is included in LibreCAD's repo.
If you want to check this out, visit this link or clone LibreCAD/LibreCAD and run git diff f08a37f282dd30ce7cb759d6cf8981c982290170.
Things like this present a serious issue for us because Spoon-Knife has 10.3k stars at the moment, while LibreCAD only has 2k.
Which means that if we were to remove the least starred project, we would actually remove LibreCAD and keep the utterly useless Spoon-Knife repo.
I hate you yourefunny.
And no, you are not actually funny.
But yourefunny is not alone in this: during our tests we've found that some people also like to merge the history of Linux and LLVM.
Go figure.
Best-effort deduplication
So we can't git clone every repo on GitHub and we can't do root-based deduplication.
What we can do is use GHTorrent once again and implement a different strategy.
In fact, GHTorrent has information about commits, too, albeit limited.
This is what it gives us:
- (partial)
(parent commit, child commit)relations. - (partial)
(commit, repository)relations.
Exploiting this data we can't reconstruct the full git history of every repository, but we can recreate subgraphs of it. We then apply this algorithm:
- Find a commit for which GHTorrent doesn't have a parent (we call them parentless commits) and consider it a root commit.
- Explore the commit history graph starting at a root commit. We do this going upward, that is, only following
parent → childedges. - We group all the repositories associated with the commits of a subgraph we obtain in step 2. We call such group a repository group.
- For every repository group, we find the most starred repo it contains and consider it the parent repo, while we consider the others the children repos. We now have several
(parent repo, child repo)relations. - We do all the previous steps for all the commits data in GHTorrent and obtain a huge graph of repositories related by
has_parentrelations. - We take all the repositories without parents and consider them unique repos. In other words, we will not crawl repos for which we have a parent.
This is easier shown than explained, so let's start with the following example git history graph:

We have 5 commits (A, B, C, D and E), related by is_parent relations, and for each commit we have data on which repos contain them.
We have 2 root commits, A and E, and for each of them we perform step 2 and 3 to create their repository groups:

You can see that we get groups Group 1 and Group 2.
We then take every group, together with the star counts of its repos, and create a partial repository graph. For example, if we take Group 2 from above, we get this:

repo4 is the repo with the most stars in Group 2, so we assume that the other repos in the group are forked from it.
By joining all the partial repository graphs we extract from all the groups we've found, we get the full repository graph:

We can now take the repositories without a parent and consider them as deduplicated repos. In other words, we will only crawl the repositories marked in red in the picture.
This is pretty much how we try to deduplicate repositories prior to cloning them. Now, before you write us angry comments: we know this is not perfect, but it works and is a good trade-off between deduplicating too much and not deduplicating at all.
From source code to string hashes
After crawling the repos resulting from the previous step, we need to analyze their C/C++ files to extract the strings inside them.
Parsing C/C++ files is non-trivial due to macros, include files, and all those C magic goodies.
In this first iteration of Big Match we wanted to be fast and favoured a simple approach: using grep (actually, ripgrep).
So yeah, we just grep for single-line string literals and store them in a txt file.
Then, we take every string from the file and de-escape it so special characters like '\n' are converted to the real ascii character they represent.
We do this because, of course, once strings pass through the compiler and end up in the final binary, they are not escaped anymore, so we try to emulate that process.
Finally, we hash the strings and store the hex-coded hashes, again, in a txt file. This is nice because we end up with 3 files per repo:
- A tarball with its source code.
- A txt file with its strings.
- A txt file with its hashes (
<repo_name>.hashes.txt)
If you are wondering why we like txt files so much, be sure to read the next section.
Polishing the data
As said above, our repository analysis pipeline leaves us with many <repo_name>.hashes.txt files containing all the hex-coded hashes of the strings in a repository.
It's now time to turn those files into something that we can use to build a search engine.
Search engine 101
A lot of modern search engines include some kind of vector space model. This is a fancy way to say that they represent a document as a vector of words. For example:
There are many flavours of vector space models, but the main point is that instead of just using a boolean value for the words, one can use word counts or some weighting scheme like tf-idf (more on this later).
What does the vector space model have to do with Big Match? Just swap repositories for documents and string hashes for words and you've got a model for building a repository search engine. And, instead of querying using a sequence of words, you just use a vector of string hashes like they were a new repository.
In our case, we decided not to count the number of times a string is present in a repository, so we just need to put a 1 if a string is present in a repo and then apply some weighting formula to tell the model that some strings are more important than others.
Now, how do you turn a bunch of txt files into a set of vectors?
Enter bashML.
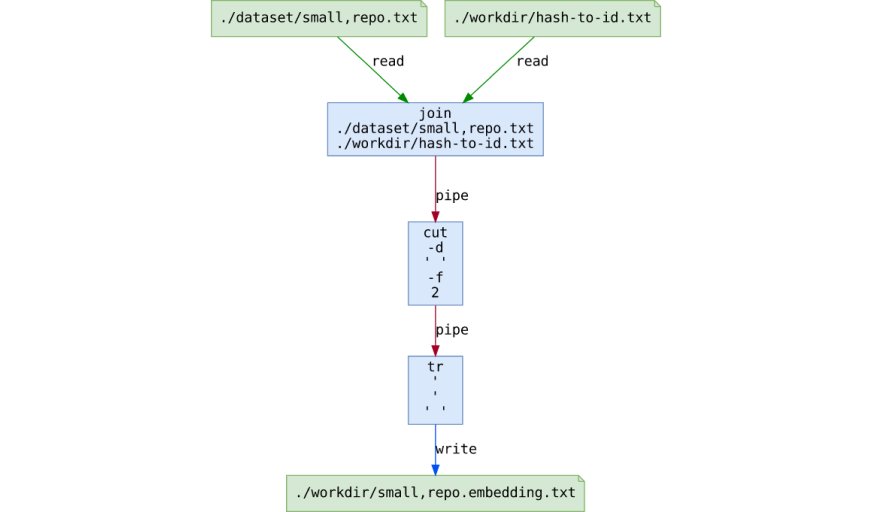
You will read about it in another article on our blog, but the main point is that we can do everything using just bash scripts by piping coreutils programs.
A picture is worth a million words, so enjoy this visualization of a part of our bash pipeline (created with our internal tool pipedream):

Algorithms and parameter estimation
The next step was to evaluate the best algorithms for weighting the strings in our repos/vectors.
For this, we created an artificial dataset using strings on libraries we compiled ourselves (thanks Gentoo).
Without going into the details, it turns out that tf-idf weighting and simple cosine similarity work very well for our problem.
For those of you unfamiliar with these terms:
- Tf-idf is a very common weighting scheme that considers both the popularity of the words in a document (in our case, string hashes in a repo) and the size of the documents (in our case, repositories). In tf-idf, popular words are penalized because it is assumed that common words convey less information than rare ones. Similarly, short documents are considered more informative than long documents, as the latters tend to match more often just because they contain more words.
- Cosine similarity, also very common, is one of the many metrics one can use to calculate the distance between vectors. Specifically, it measures the angle between a pair of N-dimensional vectors: a similarity next to 1 means a small angle, while a value close to 0 means the vectors are orthogonal.
Long story short: scoring boils down to calculating the cosine distance between a given repo and the set of hashes in input (both weighted using tf-idf).
We also wanted to study whether removing the top-K most common strings could improve the results of a query.
Our intuition was that very frequent strings like "error" aren't very useful in disambiguating repositories.
In fact, removing the most common strings did improve our results: cutting around K = 10k seemed to give the best score.
After some plotting around, we increased our confidence in that magic number:

Note: both axes use a logarithmic scale.
You can easily see that the first ~10k most frequent strings (on the left of the red line) are very popular, then there's a somewhat flat area, and finally an area of infrequent strings on the right. The graph, together with our tests, confirms that keeping the strings that are too popular actually makes the query results worse.
At this point, due to the big number of near-duplicates still present in our database, the repo similarity scores looked like this:
This is a huge problem because it means that if we just show the top-K repositories that have the highest similarity to our query, they are mostly different versions of the same repo.
If there are two repos inside our binary, for example zlib and libssl, one of the two would be buried deep down in the results due to the many zlib or libssl versions out there.
On top of that, developers often just copy zlib or libssl source code in their repos to have all dependencies ready on clone.
For these reasons we wanted to cluster the search results. We once again used our artificial Gentoo dataset, plus some manual result evaluation, and ended up choosing spectral co-clustering as our clustering algorithm. We also plotted the clustered results and they looked pretty pretty nice:

On the x-axis you have the strings that match our example query while on the y-axis you have the repositories matching at least one string hash. A red pixel means that the repo y contains string x. The blue lines are just to mark the different repository clusters. Due to the nature of spectral co-clustering, the more the plot looks like a block diagonal matrix, the better the clustering results are.
It's interesting to note that strings plus clustering are good enough to visually identify similar repositories.
One might also be able to use strings to guess if a repository is wholly contained into a bigger one (once again, think of something like zlib inside the repo of an image compression program).
Putting it into production
Putting everything we have shown into a working search engine is just a matter of loading all the repo vectors into a huge (sparse) matrix and wait for a query vector from the user. By query vector we mean that, once the user gives us a set of strings to search in Big Match, we encode them in a vector using the encoding scheme we've shown earlier.
Since we use tf-idf and normalize properly, a matrix multiplication is all we need to score every repository against the query:

where

After that we just need to use the scores to find the best-matching repositories, cluster them using their rows in the big matrix, and show everything to the user.
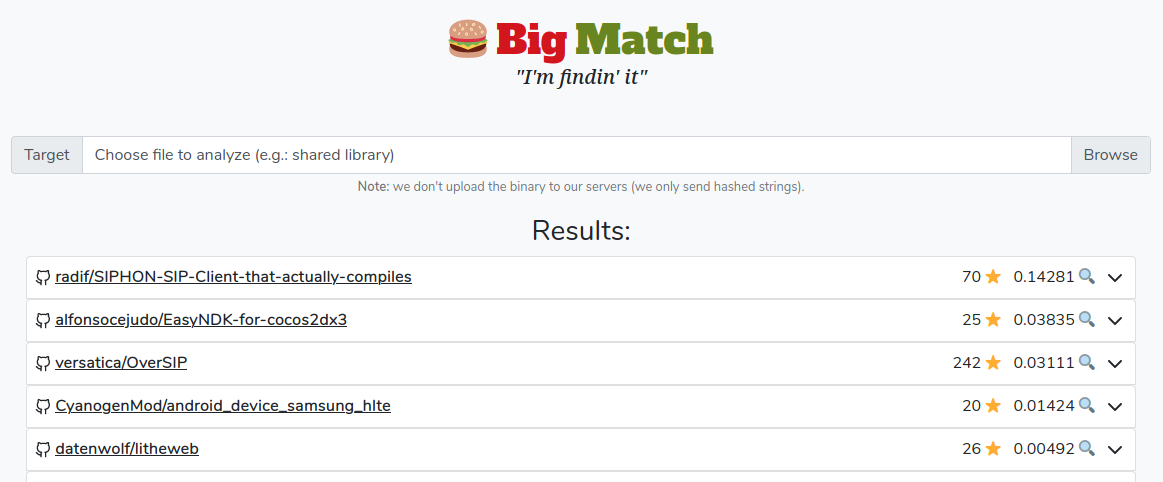
But don't take our word for it, try our amazing web demo.
A second deduplication step
When we tried out our pipeline for the first time, the average amount of RAM required to store a repo vector was around 40kB.
That's not too much, but we plan to have most of GitHub C/C++ repos in memory so we wanted to decrease it even more.
Since we use a sparse matrix, memory consumption is proportional to the number of elements we store, where an element is stored iff  .
.
In order to get a better insight into our initial dataset, we plotted the top-10k repos with the most strings to look at their string distribution:

The average string count, 23k, is shown in red in the picture. We also marked in green the position of a repository with ~23k strings, which is basically the repo with average string count. It follows that if we sum everything on the left of the green line we get (almost) the same number that we get if we sum everything on the right. In other words, the area under the blue curve (in the complete, uncropped plot) is divided evenly by the green line. If we keep in mind that at this point the dataset was made out of ~60k repositories, this means that the top-5k biggest repos occupied as much RAM as the remaining ~55k repos.
By looking at the plot we are able to say that if we are able to better deduplicate the most expensive (memory-wise) repositories we should be able to lower the average amount of memory-per-repository by quite a bit. In case you are wondering what those projects are, they are mostly Android or plain Linux kernels that are dumped on GitHub as a single commit, so they bypass our first deduplication pass.
Since at this point we have the source code of every repository that passed through the first deduplication phase, we can apply a second, more expensive, content-aware deduplication to try to improve the situation. For this, we wrote a bash script that computes the Jaccard similarity of the biggest repositories in our dataset and, given two very similar projects, only keeps the most-starred one. By using this method we are able to succesfully deduplicate a lot of big repositories and decrease RAM usage significantly.
Pros and cons
Time to talk about the good and the bad of this first iteration of Big Match.
Pros:
- Perfect string-matching works surprisingly well.
- Privacy: if a hash doesn't match, we don't know what string it represents.
Cons:
- We get relevant results only for binaries with a decent amount of strings.
- At the moment, we only do perfect matching: in the future we want to support partial matches
- Query speed is good enough but we need to make it faster as we scale up our database.
- Using
stringsis sub-optimal: a proper decompiler-driven string extraction algorithm would be able to exploit, for example, pointers in the binary to better understand where strings actually start (stringsis limited to very simple heuristics). So, instead of picking up strings with wrong prefixes like"XRWFHello World", we would be able to extract the actual string"Hello World".
Conclusion
Gone are the days of me reversers wasting weeks reversing open source libraries embedded in their targets.
Ok, maybe not yet, but we made a big step towards that goal and, while quite happy with the results of Big Match v1, we are already planning for the next iteration of the project.
First of all, we want to integrate Big Match with our decompiler. Then, we want to add partial strings matching and introduce support for magic numbers/arrays (think well-known constants like file format headers or cryptographic constants). We also want to test whether strings and constants can be reliably used to guess the exact version of a library embedded in a binary (if you have access to a library's git history, you can search for the commit that results in the best string matches). In the mean time, we need to battle-test Big Match's engine and scale the size of our database so that we can provide more value to the users. Finally, it would be interesting to add to our database strings taken directly from binaries for which there are no sources available (e.g.: firmware, malware, etc...).
One again, if you haven't done it already, go check out our Big Match demo and tell us what you think.
Until then,